Разработка операционных систем.
Введение.

 В среде разработчиков операционных систем ходит множество изустных преданий о том, что такое хорошо и что такое плохо, однако на удивление мало этих историй записано. Наиболее важной книгой можно назвать классический труд Фреда Брукса (Brooks, 1975), в котором автор делится своим опытом проектирования и реализации операционной системы IBM OS/360. Материал выпущенного к 20-летней годовщине издания был пересмотрен, к тому же в книгу было включено несколько новых глав (Brooks, 1995).
В среде разработчиков операционных систем ходит множество изустных преданий о том, что такое хорошо и что такое плохо, однако на удивление мало этих историй записано. Наиболее важной книгой можно назвать классический труд Фреда Брукса (Brooks, 1975), в котором автор делится своим опытом проектирования и реализации операционной системы IBM OS/360. Материал выпущенного к 20-летней годовщине издания был пересмотрен, к тому же в книгу было включено несколько новых глав (Brooks, 1995).
Тремя классическими трудами по проектированию операционных систем являются книги Lampson (1984), Corbato (1991), Saltzer et al. (1984). Как и книги Брукса, эти три издания успешно пережили время, прошедшее с момента их написания. Большая часть рассматриваемых в них вопросов сохранила свою актуальность и в наши дни.
Данная лекция основана на содержимом этих источников, кроме того, в ней используется личный опыт участия Эндрю Таненбаума в проектировании двух систем: Amoeba (Tanenbaum et al., 1990) и MINIX (Tanenbaum and Woodhull, 2006).
Amoeba — открытая микроядерная распределённая операционная система, разработанная группой во главе с Эндрю Таненбаумом в Амстердамском свободном университете. Amoeba не основана ни на одной из существующих операционных систем, так как разрабатывалась «с нуля».
Цель проекта Amoeba — создать систему распределённых вычислений, которая предоставляла бы пользователю сеть компьютеров как одну рабочую станцию. Как утверждается на официальном сайте, данная операционная система используется в академической среде, промышленности и правительственных организациях около 5 лет.
Amoeba может работать на нескольких аппаратных платформах: SPARC, i386, i486, 68030, Sun 3/50 и Sun 3/60.
Вопрос 1. Природа проблемы проектирования.
Разработка операционных систем представляет собой в большей мере инженерный проект, нежели точную науку. В этой области значительно труднее наметить ясные цели и достичь их. Рассмотрим для начала вопрос постановки задачи.
Цели
Чтобы проект операционной системы был успешным, разработчики должны иметь четкое представление о том, чего они хотят. При отсутствии цели очень трудно принимать последующие решения. Чтобы этот вопрос стал понятнее, полезно взглянуть на два языка программирования, PL/1 и C. Язык PL/1 был разработан корпорацией IBM в 1960-е годы, так как поддерживать одновременно FORTRAN и COBOL и слышать при этом за спиной ворчание ученых о том, что Algol лучше, чем FORTRAN и COBOL вместе взятые, было невыносимо. Поэтому был образован комитет для создания нового языка, удовлетворяющего запросам всех программистов: PL/1. Этот язык обладал некоторыми чертами языка FORTRAN, некоторыми особенностями языка COBOL и некоторыми свойствами языка Algol. Проект потерпел неудачу, потому что ему недоставало единой концепции. Проект представлял собой набор свойств, конфликтующих друг с другом, к тому же язык PL/1 был слишком громоздким и неуклюжим, чтобы программы на нем можно было эффективно компилировать.
 Теперь взглянем на язык C. Он был спроектирован всего одним человеком, Деннисом Ритчи, для единственной цели — системного программирования. Успех его был колоссален, и это не в последнюю очередь объяснялось тем, что Ритчи знал, чего хотел, а чего не хотел. В результате спустя десятилетия после своего появления этот язык все еще широко распространен. Наличие четкого представления о своих целях является решающим.
Теперь взглянем на язык C. Он был спроектирован всего одним человеком, Деннисом Ритчи, для единственной цели — системного программирования. Успех его был колоссален, и это не в последнюю очередь объяснялось тем, что Ритчи знал, чего хотел, а чего не хотел. В результате спустя десятилетия после своего появления этот язык все еще широко распространен. Наличие четкого представления о своих целях является решающим.
Чего же хотят разработчики операционных систем? Очевидно, ответ варьируется от системы к системе и будет разным для встроенных и серверных систем. Для универсальных операционных систем основными являются следующие четыре пункта:
- Определение абстракций.
- Предоставление примитивных операций.
- Обеспечение изоляции.
- Управление аппаратурой.
Далее будет рассмотрен каждый из этих пунктов.
Наиболее важная, но, вероятно, наиболее сложная задача операционной системы заключается в определении правильных абстракций. Некоторые из них, такие как процессы и файлы, используются уже так давно, что могут показаться очевидными. Другие, такие как потоки исполнения, представляют собой более новые и потому не столь устоявшиеся понятия. Например, если состоящий из нескольких потоков процесс, один из потоков которого блокирован вводом с клавиатуры, клонируется, то должен ли поток в новом процессе также ожидать ввода с клавиатуры? Другие абстракции относятся к синхронизации, сигналам, модели памяти, моделированию ввода-вывода и иным областям.
Каждая абстракция может быть реализована в виде конкретных структур данных. Пользователи могут создавать процессы, файлы, каналы и т. д. Управляют этими структурами данных при помощи примитивных операций. Например, пользователи могут читать и писать файлы. Примитивные операции реализуются в виде системных вызовов. С точки зрения пользователя, сердце операционной системы формируется абстракциями, а операции над ними возможны при помощи системных вызовов.
Поскольку на одном компьютере могут одновременно зарегистрироваться несколько пользователей, операционная система должна предоставлять механизмы для отделения их друг от друга. Один пользователь не должен вмешиваться в работу другого. Концепция процессов широко используется для группирования ресурсов с целью их защиты. Как правило, защищаются файлы и другие структуры данных. Еще одним местом, где разделение играет весьма важную роль, является виртуализация: гипервизор должен обеспечить обособленность виртуальных машин от всех сложностей работы других виртуальных машин. Ключевая цель проектирования операционной системы заключается в том, чтобы гарантировать, что каждый пользователь может выполнять только разрешенные ему действия с данными, к которым у него есть право доступа. Однако пользователям бывает необходимо совместное использование данных и ресурсов, поэтому изоляция должна быть избирательной и контролироваться пользователями. Все это существенно усложняет устройство операционной системы. Почтовые программы не должны наносить вред веб-браузерам. Даже если существует только один пользователь, разные процессы должны быть разделены. Чтобы защитить процессы друг от друга, на некоторых системах, таких как Android, каждый процесс, принадлежащий одному и тому же пользователю, будет запускаться с иным пользовательским идентификатором.
С этим вопросом тесно связана проблема изолирования отказов. Если какая-либо часть системы выйдет из строя (чаще всего это один из пользовательских процессов), то сбойный процесс не должен нарушить работу всей операционной системы. Устройство операционной системы должно гарантировать изоляцию различных частей операционной системы друг от друга, чтобы их сбои были независимыми. Заходя еще дальше, можно задаться вопросом: а не должна ли операционная система быть устойчивой к сбоям и самоисцеляющейся?
Наконец, операционная система должна управлять аппаратурой. В частности, она должна заботиться обо всех низкоуровневых микросхемах, таких как контроллеры прерываний и контроллеры шин. Она также должна обеспечивать каркас для того, чтобы драйверы устройств могли управлять крупными устройствами ввода-вывода, такими как диски, принтеры и дисплей.
Почему так сложно спроектировать операционную систему?
Закон Мура гласит, что аппаратное обеспечение компьютера увеличивает свою производительность в 100 раз каждые 10 лет. Никто, к сожалению, так и не сформулировал ничего подобного для программного обеспечения. Никто не говорит даже, что операционные системы вообще совершенствуются с годами. В самом деле, можно утверждать, что часть из них в некоторых аспектах (таких, как надежность) стали даже хуже, чем, например, операционная система UNIX Version 7 образца 1970-х 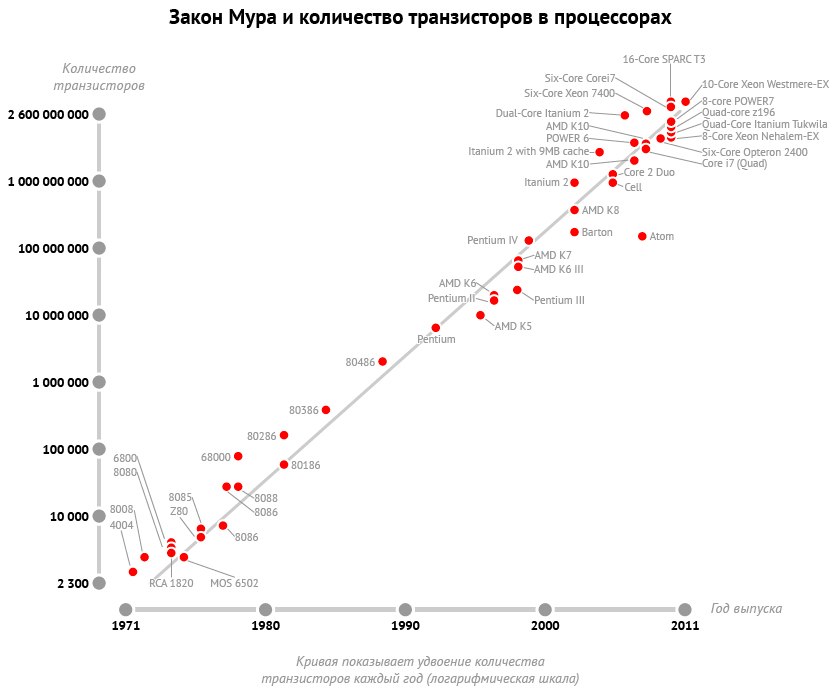 годов.
годов.
Почему? Как правило, основными причинами оказываются инерция и желание сохранить обратную совместимость, хотя неумение разработчиков придерживаться принципов хорошего проектирования тоже вносит свою лепту. Но этот вопрос следует обсудить подробнее. Операционные системы принципиально отличаются от небольших прикладных программ.
Рассмотрим восемь аспектов, благодаря которым разработка операционной системы оказывается значительно сложнее написания прикладной программы.
Во-первых, операционные системы стали крайне громоздкими программами. Никто в одиночку не может за несколько месяцев написать операционную систему. Или даже за несколько лет. Все современные версии UNIX содержат миллионы строк кода; объем Linux, к примеру, достигает 15 млн. В Windows 8, наверное, от 50 до 100 млн строк кода, в зависимости от того, что брать в расчет (у Vista было 70 млн, но это количество изменялось, поскольку код как добавлялся, так и удалялся). Ни один человек на Земле не способен понять миллион строк, не говоря уже о 50 или 100 млн. Если вы создаете продукт, который ни один из разработчиков не может даже надеяться понять целиком, неудивительно, что результаты часто оказываются далеки от оптимальных.
 Операционные системы не являются самыми сложными системами в мире. Авианосцы, например, представляют собой значительно более сложные системы, но они намного легче разделяются на отдельные подсистемы. Проектировщики туалетов на авианосце не должны заниматься радарной системой. Эти две подсистемы почти не взаимодействуют. История не знает случаев, когда забитый туалет на авианосце служил причиной запуска ракет. В операционной же системе файловая система часто взаимодействует с системой памяти самым неожиданным и непредсказуемым образом.
Операционные системы не являются самыми сложными системами в мире. Авианосцы, например, представляют собой значительно более сложные системы, но они намного легче разделяются на отдельные подсистемы. Проектировщики туалетов на авианосце не должны заниматься радарной системой. Эти две подсистемы почти не взаимодействуют. История не знает случаев, когда забитый туалет на авианосце служил причиной запуска ракет. В операционной же системе файловая система часто взаимодействует с системой памяти самым неожиданным и непредсказуемым образом.
Во-вторых, операционные системы должны учитывать параллелизм. В системе одновременно присутствует множество пользователей, работающих с множеством устройств ввода-вывода. Управление несколькими параллельно выполняющимися процессами существенно сложнее управления одной последовательной деятельностью. Среди множества возникающих при этом проблем достаточно назвать хотя бы состязания и тупиковые ситуации.
В-третьих, операционные системы должны учитывать наличие потенциально враждебных пользователей, желающих вмешиваться в работу операционной системы или выполнять запрещенные действия, например похищение чужих файлов. Операционная система должна предпринимать меры для предотвращения подобных действий со стороны злонамеренных пользователей. Текстовые процессоры и фоторедакторы не сталкиваются с подобными проблемами.
В-четвертых, несмотря на тот факт, что пользователи друг другу не доверяют, многим из них бывает нужно использовать какую-либо информацию или ресурсы совместно с определенной группой пользователей. Операционная система должна предоставлять эту возможность, но таким образом, чтобы злоумышленник не смог воспользоваться этими свойствами для своих целей. У прикладных программ подобных проблем тоже нет.
В-пятых, операционные системы, как правило, живут довольно долго. Операционная система UNIX используется уже более 40 лет, система Windows используется около 30 лет и не подает признаков того, что собирается уходить в историю. Соответственно проектировщики операционной системы должны думать о том, как могут измениться аппаратура и приложения в отдаленном будущем и как им следует к этому подготовиться. Системы, отражающие одно специфическое мировоззрение, как правило, быстро сходят со сцены.
В-шестых, у разработчиков операционной системы на самом деле нет четкого представления о том, как будет использоваться их система, поэтому они должны обеспечить достаточную степень универсальности. При проектировании таких систем, как UNIX или Windows, их использование для работы с веб-браузером или с потоковым видео высокого разрешения не предполагалось, однако многие современные компьютеры в основном только для этого и используются. Трудно себе представить проектировщика морского судна, который не знал бы, что он проектирует: рыболовецкое судно, пассажирское судно или военный корабль.
В-седьмых, от современных операционных систем, как правило, требуется переносимость, что означает возможность работы на различных платформах. Они также должны поддерживать сотни или даже тысячи устройств ввода-вывода, которые проектируются совершенно независимо друг от друга. Например, операционная система должна работать на компьютерах как с прямым, так и с обратным порядком байтов. Второй пример постоянно наблюдался в системе MS-DOS, когда пользователи пытались установить звуковую карту и модем, использующие одни и те же порты ввода-вывода или линии запроса прерывания. С такими проблемами, как конфликты различных частей аппаратуры, приходится иметь дело в основном именно операционным системам.
Наконец, в-восьмых, при разработке операционных систем часто учитывается необходимость совместимости с предыдущей версией операционной системы. Система может иметь множество ограничений на длину слов, имена файлов и т. д., рассматриваемых теперь проектировщиками как устаревшие, но от которых трудно избавиться. Это напоминает переоборудование автомобильного завода под выпуск новых моделей с условием сохранения существующих мощностей по выпуску старых моделей.
Вопрос 2. Разработка интерфейса и производительность.
Итак, теперь должно быть ясно, что написание современной операционной системы представляет собой непростую задачу. Но с чего начинается эта работа? Возможно, лучше всего сначала подумать о предоставляемых операционной системой интерфейсах. Операционная система предоставляет набор служб, большую часть типов данных (например, файлы) и множество операций с ними (например, read). Вместе они формируют интерфейс пользователей системы. Обратите внимание на то, что в данном контексте пользователями операционной системы являются программисты, пишущие программы, которые используют системные вызовы, а не люди, запускающие прикладные программы.
Кроме основного интерфейса системных вызовов у большинства операционных систем есть дополнительные интерфейсы. Например, некоторым программистам не обходимо бывает написать драйвер устройства, чтобы добавить его в операционную систему. Эти драйверы предоставляют определенные функции и могут обращаться к определенным системным вызовам. Функции и вызовы определяют интерфейс, существенно отличающийся от используемого прикладными программистами. Все эти интерфейсы должны быть тщательно спроектированы, если разработчики системы рассчитывают на успех.
Руководящие принципы
Существуют ли принципы, руководствуясь которыми можно проектировать интерфейсы? Мы надеемся, что такие принципы есть. Если выразить их в нескольких словах, то это простота, полнота и возможность эффективной реализации.
Принцип 1: простота
Простой интерфейс легче понять и реализовать без ошибок. Всем разработчикам систем следует помнить эту знаменитую цитату французского летчика и писателя Антуана де Сент-Экзюпери: «Совершенство достигается не тогда, когда уже больше нечего добавить, а когда больше нечего убавить».
Этот принцип утверждает, что лучше меньше, чем больше, по крайней мере, применительно к операционным системам. Другими словами, этот принцип может быть выражен аббревиатурой KISS (Keep It Simple, Stupid), предлагающей программисту, в чьих мыслительных способностях возникают сомнения, не усложнять систему.
Принцип 2: полнота
Разумеется, интерфейс должен предоставлять пользователям возможность выполнять все, что им необходимо, то есть интерфейс должен обладать полнотой. В связи с этим на ум приходит другая цитата, на этот раз это фраза, сказанная Альбертом Эйнштейном:
«Все должно быть простым, насколько это возможно, но не проще».
Другими словами, операционная система должна выполнять то, что от нее требуется, но не более того. Если пользователю нужно хранить данные, операционная система должна предоставлять для этого некий механизм. Если пользователям необходимо общаться друг с другом, операционная система должна предоставлять механизм общения и т. д. В своей речи по поводу получения награды Turing Award один из разработчиков систем CTSS и MULTICS Фернандо Корбато объединил понятия простоты и полноты и сказал: «Во-первых, важно подчеркнуть значение простоты и элегантности, так как сложность приводит к нагромождению противоречий и, как мы уже видели, появлению ошибок. Я бы определил элегантность как достижение заданной функциональности при помощи минимума механизма и максимума ясности».
Ключевая идея здесь — минимум механизма. Другими словами, каждая функция, каждый системный вызов должны нести собственную ношу. Когда член команды проектировщиков предлагает расширить системный вызов или добавить новую функцию, остальные разработчики должны спросить его: «Произойдет ли что-нибудь ужасное, если мы этого не сделаем?». Если ответом будет: «Нет, но, возможно, когда-нибудь кто-то посчитает эту функцию полезной», — поместите ее в библиотеку уровня пользователя, а не в операционную систему, даже если при этом она будет работать медленнее. Не должна ставиться задача сделать каждую функцию быстрее пули. Цель заключается в том, чтобы сохранить то, что Корбато назвал минимумом механизма.
Принцип 3: эффективность
Третий руководящий принцип представляет собой эффективность реализации. Если какая-либо функция (или системный вызов) не может быть реализована эффективно, вероятно, ее не следует реализовывать. Программист должен интуитивно представлять стоимость реализации и использования каждого системного вызова. Например, программисты, пишущие программы в системе UNIX, считают, что системный вызов lseek дешевле системного вызова read, так как первый системный вызов просто изменяет содержимое указателя, хранящегося в памяти, тогда как второй выполняет операцию дискового ввода-вывода. Если интуиция подводит программиста, программист создает неэффективные программы.
Парадигмы
Когда цели установлены, можно начинать проектирование. Можно начать, например, со следующего: подумать, какой предстанет система перед пользователями. Один из наиболее важных вопросов заключается в том, чтобы все функции системы хорошо согласовывались друг с другом и обладали тем, что часто называют архитектурной согласованностью. При этом важно различать два типа пользователей операционной системы. С одной стороны, существуют пользователи, взаимодействующие с прикладными программами, с другой — есть программисты, пишущие эти прикладные программы. Первые большей частью имеют дело с графическим интерфейсом пользователя, тогда как последние в основном взаимодействуют с интерфейсом системных вызовов. Если задача заключается в том, чтобы иметь единый графический интерфейс пользователя, заполняющий всю систему, как, например, в системе Macintosh, то разработку следует начать отсюда. Если же цель состоит в том, чтобы обеспечить поддержку различных возможных графических интерфейсов пользователя как в системе UNIX, то в первую очередь должен быть разработан интерфейс системных вызовов. Начало разработки системы с графического интерфейса пользователя представляет собой, посути, проектирование сверху вниз. Вопрос заключается в том, какие функции будет этот интерфейс иметь, как будет пользователь с ними взаимодействовать и как следует спроектировать систему для их поддержки. Например, если большинство программ отображает на экране значки, а затем ждет, когда пользователь щелкнет на них мышью, это предполагает использование управляемой событиями модели для графического интерфейса пользователя и, возможно, для операционной системы. В то же время если экран в основном заполнен текстовыми окнами, то, вероятно, лучшей представляется модель, в которой процессы считывают символы с клавиатуры.
Реализация в первую очередь интерфейса системных вызовов представляет собой проектирование снизу вверх. Здесь вопросы заключаются в том, какие функции нужны программистам. В действительности для поддержки графического интерфейса пользователя требуется не так уж много специальных функций. Например, оконная система под названием X Windows, используемая в UNIX, представляет собой просто большую программу на языке C, которая обращается к клавиатуре, мыши и экрану с системными вызовами read и write. Оконная система X Windows была разработана значительно позже операционной системы UNIX, но для ее работы не потребовалось большого количества изменений в операционной системе. Это подтверждает тот факт, что система UNIX обладает полнотой в достаточной степени.
Парадигмы интерфейса пользователя
Как для интерфейса уровня графического интерфейса пользователя, так и для интерфейса системных вызовов наиболее важный аспект заключается в наличии хорошей парадигмы (иногда называемой метафорой или модельным представлением), обеспечивающей наглядный зрительный образ интерфейса. Многими графическими интерфейсами пользователя используется парадигма WIMP (Windows, Icons, Menus, Pointers — окна, пиктограммы, меню, указатели). Эта парадигма используется в интерфейсе для обеспечения согласованности таких идиом, как щелчок и двойной щелчок мышью, перетаскивание и т. д. Часто к программам предъявляются дополнительные требования, такие как наличие строки меню с пунктами Файл, Правка и т. д., каждый из которых содержит хорошо знакомые пункты меню. Таким образом, пользователи, знакомые с одной программой, легко могут освоить другую программу.
Однако пользовательский интерфейс WIMP не является единственно возможным. Планшетные компьютеры, смартфоны и некоторые ноутбуки используют сенсорные экраны, позволяющие пользователям взаимодействовать с устройством более непосредственным и интуитивно понятным образом. На некоторых карманных компьютерах используется стилизованный интерфейс рукописного ввода. В специализированных мультимедийных устройствах может использоваться интерфейс видеомагнитофона. И конечно же, совершенно иная парадигма используется при голосовом вводе. Самое важное относится не столько к выбору парадигмы, сколько к факту наличия единственной, самой важной парадигмы, объединяющей весь пользовательский интерфейс.
Какая бы парадигма ни была выбрана, важно, чтобы все прикладные программы использовали ее. Следовательно, проектировщики системы должны предоставить разработчикам прикладных программ библиотеки и инструменты для доступа к процедурам, обеспечивающим однородный внешний вид пользовательского интерфейса.
Без инструментария разработчики приложений все будут делать по-своему.
Парадигмы исполнения
Архитектурная согласованность важна на уровне пользователя, но в равной мере она важна на уровне интерфейса системных вызовов. Здесь часто полезно различать парадигму исполнения и парадигму данных, поэтому мы рассмотрим и ту и другую, начав с первой.
Широкое распространение получили две парадигмы: алгоритмическая и движимая событиями. Алгоритмическая парадигма основана на идее, что программа запускается для выполнения некоторой функции, известной заранее или задаваемой в виде параметров. Эта функция может заключаться в компиляции программы, составлении ведомости или пилотировании самолета до Владивостока. Базовая логика жестко прошита в код программы, при этом программа время от времени обращается к системным вызовам, чтобы получить ввод пользователя, обратиться к системным службам и т. д. Этот подход проиллюстрирован в листинге 1, а.
 Другая парадигма исполнения представляет собой парадигму управления событиями (листинг 1, б). Здесь программа выполняет определенную инициализацию, напри мер отображает какое-либо окно, а затем ждет, когда операционная система сообщит ей о первом событии. Этим событием может быть нажатие клавиши или перемещение мыши. Такая схема полезна для программ, активно взаимодействующих с пользователем.
Другая парадигма исполнения представляет собой парадигму управления событиями (листинг 1, б). Здесь программа выполняет определенную инициализацию, напри мер отображает какое-либо окно, а затем ждет, когда операционная система сообщит ей о первом событии. Этим событием может быть нажатие клавиши или перемещение мыши. Такая схема полезна для программ, активно взаимодействующих с пользователем.
Листинг 1. Код: а — алгоритмический; б — движимый событиями.
Каждая парадигма порождает собственный стиль программирования. В алгоритмической парадигме алгоритмы занимают центральное положение, а операционная система рассматривается как поставщик служб. В парадигме управления событиями операционная система также предоставляет службы, но ее основная роль заключается в координации активности пользователя и формировании событий, потребляемых процессами.
Парадигмы данных
 Парадигма исполнения является не единственной парадигмой, экспортируемой операционной системой. Не менее важна парадигма данных. Ключевой вопрос здесь заключается в том, как предстают перед программистом системные структуры и устройства. В ранних пакетных системах, предназначенных для выполнения программ на языке FORTRAN, все моделировалось как логическая магнитная лента. Считываемые колоды карт воспринимались как входные ленты, пробиваемые колоды карт обрабатывались как выходные ленты.
Парадигма исполнения является не единственной парадигмой, экспортируемой операционной системой. Не менее важна парадигма данных. Ключевой вопрос здесь заключается в том, как предстают перед программистом системные структуры и устройства. В ранних пакетных системах, предназначенных для выполнения программ на языке FORTRAN, все моделировалось как логическая магнитная лента. Считываемые колоды карт воспринимались как входные ленты, пробиваемые колоды карт обрабатывались как выходные ленты.
Вывод на принтер также обрабатывался как выходная лента. Файлы на диске также считались лентами. Произвольный доступ к файлу был возможен только при помощи перемотки соответствующей ленты и повторного считывания.
Задание запускалось при помощи карт управления заданием, например:
MOUNT(TAPE08, REEL781)
RUN(INPUT, MYDATA, OUTPUT, PUNCH, TAPE08)
Первая карта представляла собой инструкцию для оператора. Он должен был достать из шкафа бобину номер 781 и установить ее на накопителе 8. Вторая карта являлась командой операционной системе запустить только что откомпилированную с языка FORTRAN программу, отображая INPUT (означающий устройство чтения перфокарт) на логическую ленту 1, дисковый файл MYDATA — на логическую ленту 2, принтер OUTPUT — на логическую ленту 3, перфоратор PUNCH — на логическую ленту 4 и физический накопитель на магнитной ленте TAPE08 — на логическую ленту 5.
У языка FORTRAN был четко определенный синтаксис, позволявший читать и писать логические ленты. При чтении с логической ленты 1 программа получает ввод с перфокарт. При помощи записи на логическую ленту 3 программа может вывести результаты на принтер. Обращаясь к логической ленте 5, программа может читать и писать магнитную ленту 781 и т. д. Обратите внимание на то, что идея магнитной ленты представляла собой всего лишь парадигму (модель) для объединения устройства чтения перфокарт, принтера, перфоратора, дисковых файлов и магнитофонов. В данном примере только логическая лента 5 была физической лентой. Все остальное представ ляло собой обычные файлы для подкачки данных. Это была примитивная парадигма, но она была шагом в правильном направлении.
Затем появилась операционная система UNIX, которая пошла значительно дальше в этом направлении, используя модель «всё суть файлы». При использовании этой парадигмы все устройства ввода-вывода рассматриваются как файлы, которые можно открывать и которыми можно управлять как обычными файлами. Операторы на языке C
fd1 = open(«file1», O_RDWR);
fd2 = open(«/dev/tty», O_RDWR);
открывают настоящий дисковый файл и терминал пользователя. Последующие операторы могут использовать дескрипторы файлов fd1 и fd2, чтобы читать из этих файлов и писать в них. С этого момента нет разницы между доступом к файлу и доступом к терминалу, не считая того, что при обращении к терминалу не разрешается операция перемещения указателя в файле.
Операционная система UNIX не только объединяет файлы и устройства ввода-вывода, но также позволяет получать доступ к другим процессам через каналы как к файлам. Более того, если поддерживается отображение файлов на адресное пространство памяти, процесс может обращаться к своей виртуальной памяти так, как если бы это был файл. Наконец, в версиях UNIX, поддерживающих файловую систему /proc, строка на языке C
fd3 = open(«/proc/501», O_RDWR);
позволяет процессу (попытаться) получить доступ к памяти процесса 501 для чтения и записи при помощи дескриптора файла fd3, что может быть полезно, например, при отладке программы.
Разумеется, только то, что кто-то сказал, что всё является файлами, не означает, что это касается абсолютно всего. Например, сетевые сокеты UNIX могут чем-то напоминать файлы, но у них есть существенное отличие, API-интерфейс сокетов. Еще в одной операционной системе, Plan 9 от компании Bell Labs, на компромисс не пошли и не предоставили специализированных интерфейсов для сетевых сокетов. В результате конструкция Plan 9 оказалась, наверное, чище.
Операционная система Windows старается все сделать похожим на объект. Получив дескриптор файла, процесса, семафора, почтового ящика или другого объекта ядра, процесс может выполнять с этим объектом различные действия. Эта парадигма является еще более общей, чем используемая в UNIX, и значительно более общей, чем в FORTRAN.
Объединяющие парадигмы встречаются и в других контекстах. Следует отметить один из них — Всемирную паутину (Web). Используемая в Паутине парадигма состоит в том, что все киберпространство заполнено документами, у каждого из которых есть свой адрес URL. Обратившись по соответствующему указателю URL (введя его с клавиатуры или щелкнув мышью по ссылке), вы получаете этот документ. В действительности многие «документы» вовсе не являются документами, но формируются программой или сценарием оболочки, когда поступает запрос. Например, когда пользователь запрашивает в интернет-магазине список компакт-дисков конкретного исполнителя, документ создается на лету программой. Его совершенно точно не существовало до того, как был получен запрос.
Итак, мы рассмотрели четыре парадигмы, а именно: всё суть ленты, файлы, объекты или документы. Во всех четырех случаях задача заключается в том, чтобы унифицировать данные, устройства или другие ресурсы для упрощения работы с ними. Каждая операционная система должна иметь подобную унифицирующую парадигму данных.
Интерфейс системных вызовов
Если исходить из высказанного Корбато принципа минимального механизма, то операционная система должна предоставлять настолько мало системных вызовов, насколько это возможно (необходимый минимум), и каждый системный вызов должен быть на столько прост, насколько это возможно (но не проще). Объединяющая парадигма данных может играть главную роль в этом. Например, если файлы, процессы, устройства ввода-вывода и прочее будут выглядеть как файлы или объекты, все они могут читаться при помощи всего одного системного вызова read. В противном случае пришлось бы иметь различные системные вызовы, такие как read_file, read_proc, read_tty и т. д.
В некоторых случаях могут потребоваться несколько вариантов системных вызовов, но, как правило, на практике лучше иметь один системный вызов, обрабатывающий общий случай, с различными библиотечными процедурами, скрывающими этот факт от программистов. Например, в операционной системе UNIX есть системный вызов exec для замены виртуального адресного пространства процесса. Наиболее общий вариант его использования выглядит следующим образом:
exec(name, argp, envp);
Данный системный вызов загружает исполняемый файл name и передает ему аргументы, на которые указывает argp, и список переменных окружения, на который указывает envp. Иногда бывает удобнее явно перечислить аргументы, поэтому в библиотеках содержатся процедуры, вызываемые следующим образом:
execl(name, arg0, arg1, …, argn, 0); execle(name, arg0, arg1, …, argn, envp);
Эти процедуры всего лишь помещают аргументы в массив, после чего обращаются к системному вызову exec, который и выполняет всю работу. Такая схема является лучшей в обоих смыслах: благодаря единственному простому системному вызову операционная система сохраняет свою простоту, в то же самое время программист получает возможность обращаться к системному вызову exec различными способами.
Разумеется, пытаясь использовать один единственный системный вызов для всех случаев жизни, легко дойти до крайностей. Для создания процесса в операционной системе UNIX требуются два системных вызова: fork, за которым следует exec. У первого вызова нет параметров, у второго вызова три параметра. Для сравнения: у вызова WinAPI для создания процесса CreateProcess 10 параметров, один из которых представляет собой указатель на структуру с дополнительными 18 параметрами.
Давным-давно следовало задать вопрос: «Произойдет ли катастрофа, если мы опустим что-нибудь из этого?» Правдивый ответ должен был звучать так: «В некоторых случаях программист будет вынужден совершить больше работы для достижения определенного эффекта, зато мы получим более простую, компактную и надежную операционную систему». Конечно, человек, предлагающий версию с этими 10 + 18 параметрами, мог добавить: «Но пользователям нравятся все эти возможности». Возразить на это можно было бы так: «Еще больше им нравятся системы, которые используют мало памяти и никогда не ломаются». Компромисс, заключающийся в большей функциональности за счет использования большего объема памяти, по крайней мере, виден невооруженным глазом, и ему можно дать оценку (так как стоимость памяти известна). Однако трудно оценить количество дополнительных сбоев в год, которые появятся благодаря внедрению новой функции. Кроме того, неизвестно, сделали бы пользователи тот же выбор, если им заранее была известна эта скрытая цена. Этот эффект можно резюмировать первым законом программного обеспечения Таненбаума: «При увеличении размера программы количество содержащихся в ней ошибок также увеличивается».
Когда к программе добавляются новые функции, к ней добавляются и новые процедуры, а вместе с ними и новые ошибки. Программисты, полагающие, что при добавлении новых функций к программе не добавится новых ошибок, либо являются новичками в программировании, либо верят, что за ними присматривает добрая фея.
Простота является не единственным принципом, которым следует руководствоваться при разработке системных вызовов. Следует также помнить о фразе, сказанной Б. Лэмпсоном в 1984 году: «Не скрывай мощь».
Если у аппаратного обеспечения есть крайне эффективный способ выполнить что либо, программистам следует предоставить простой доступ к этой возможности, а не хоронить ее внутри некой абстракции. Назначение абстракций заключается в том, чтобы скрывать нежелательные свойства, а не полезные свойства. Например, предположим, что у аппаратуры есть специальный способ перемещения больших участков изображений по экрану (то есть в видеопамяти) на высокой скорости. В этом случае ввод нового системного вызова, предоставляющего доступ к этому механизму, будет оправдан, так как это лучше, чем читать данные из видео-ОЗУ в обычную память, а за тем писать эти данные обратно в видео-ОЗУ. Новый вызов должен просто перемещать биты в видеопамяти. Если этот новый системный вызов будет быстрым, это позволит пользователям создавать более эффективные программы. Если системный вызов мед ленный, никто не будет им пользоваться.
При проектировании системы возникает также вопрос использования ориентированных на соединение вызовов или вызовов, не использующих соединений. Системные вызовы Windows и UNIX для чтения файлов являются ориентированными на соединение, что похоже на использование телефона. Сначала вы открываете файл, затем читаете его и, наконец, закрываете файл. Некоторые протоколы работы с удаленными файлами также являются ориентированными на соединение. Например, чтобы использовать протокол FTP, пользователь сначала регистрируется на удаленной машине, читает файлы, а затем выходит из системы.
В то же время некоторые протоколы удаленного доступа к файлам не требуют соединений. Веб-протокол (HTTP) не требует соединений. Чтобы прочитать веб-страницу, вы просто запрашиваете ее. Не требуется никаких предварительных настроек (TCP соединение все-таки требуется, но оно представляет собой более низкий уровень протокола; протокол HTTP, используемый для доступа к самой веб-странице, не требует соединений).
От того, какой из механизмов выбрать — ориентированный на соединение или не требующий соединений, — зависит, будет ли от механизма требоваться дополнительная работа (например, по открытию файлов) или же эта работа перекладывается на плечи использующей механизм прикладной программы. В последнем случае получается существенный выигрыш в эффективности, если к одному и тому же файлу программа обращается много раз. Для системы ввода-вывода на одной машине, где стоимость подготовки ввода-вывода (открытия файла) низка, вероятно, лучше использовать стандартный способ (сначала открыть, затем использовать). Для удаленных файловых систем возможно использование обоих вариантов.
Другой вопрос, возникающий при проектировании интерфейса системных вызовов, заключается в его открытости. Список системных вызовов, определяемых стандартом POSIX, легко найти. Эти системные вызовы поддерживаются всеми системами UNIX, как и небольшое количество других вызовов, но полный список всегда публикуется. Корпорация Microsoft, напротив, никогда не публиковала список системных вызовов Windows. Вместо этого публикуются функции интерфейса WinAPI, а также вызовы других интерфейсов. Эти списки содержат огромное количество библиотечных вы зовов (более 10 000), но только малое их число являются настоящими системными вызовами. Аргумент в пользу открытости системных вызовов заключается в том, что программистам становится известна цена использования функций. Функции, исполняемые в пространстве пользователя, выполняются быстрее, чем те, которые требуют переключения в режим ядра. Закрытость системных вызовов также имеет свои преимущества, заключающиеся в том, что в результате достигается гибкость в реализации библиотечных процедур. То есть разработчики операционной системы получают возможность изменять действительные системные вызовы, сохраняя при этом работоспособность прикладных программ.
Вопрос 3. Производительность
При прочих равных условиях быстрая операционная система лучше медленной. Однако быстрая, но ненадежная операционная система хуже надежной, но медленной. Поскольку сложные оптимизирующие методы часто приводят к появлению в системе новых ошибок, не следует злоупотреблять оптимизацией. И все же существуют области, в которых производительность является критичной, и оптимизация стоит затрачиваемых усилий. Мы рассмотрим несколько методов, которые могут применяться для повышения производительности там, где это нужно.
Почему операционные системы такие медленные?
Прежде чем перейти к разговору о методах оптимизации, имеет смысл отметить, что в медлительности работы многих операционных систем во многом виноваты сами операционные системы. Например, старые операционные системы, такие как MS DOS и UNIX Version 7, загружались за несколько секунд. Для загрузки современных версий систем UNIX и Windows 8 требуется несколько минут, несмотря на то что они загружаются на аппаратуре, работающей в тысячу раз быстрее. Причина состоит в том, что новые системы выполняют гораздо больше действий, нужно это или нет. Например, Plug and Play облегчает установку новых аппаратных устройств, но платой за это является то, что при каждой загрузке операционная система должна исследовать все аппаратное обеспечение, чтобы определить, не появилось ли что-либо новое. Сканирование шин занимает время.
Альтернативный подход заключается в том, чтобы совсем выбросить Plug and Play, а на экране установить значок Установка новой аппаратуры. Установив новое аппаратное устройство, пользователь просто щелкает мышью на этом значке, запуская процедуру сканирования шин, вместо того чтобы разрешать операционной системе делать это при каждой загрузке. Разработчики операционных систем, безусловно, знали о наличии такой возможности. Однако они отказались от нее, в основном потому, что считали пользователей недостаточно умными, чтобы правильно выполнить требуемые действия.
Это всего лишь один пример, но можно привести множество других примеров того, как желание сделать систему «дружественной по отношению к пользователю» (или «защищенной от дурака», в зависимости от ваших лингвистических предпочтений) значительно снижало производительность системы.
Вероятно, больше всего могут добиться разработчики систем в деле увеличения производительности, если существенно повысят избирательность при добавлении к системе новых функций. Вопрос, который должен при этом ставиться, не «понравится ли это пользователям?», а «стоит ли добавление этой функции той неизбежной платы, заключающейся в увеличении программы, снижении скорости, увеличении сложности и снижении надежности?» Следует включать новую функцию, только если преимущества со всей очевидностью перевешивают недостатки. Некоторые программисты склонны предполагать, что размеры программы будут равны нулю, а скорость ее работы будет бесконечной. Как показывают эксперименты, эта точка зрения является несколько оптимистичной.
Другой фактор, также играющий роль в данном вопросе, заключается в рыночной стратегии производителей программного обеспечения. К тому времени, когда версия 4 или 5 некоего программного продукта попадает на рынок, все нужные новые функции, включенные в эту версию, у потребителей, вероятно, уже будут. Чтобы не снижать уровень продаж, многие производители продолжают выпускать новые версии с большим количеством функций. Добавление новых функций просто ради добавления новых функций может помочь увеличению продаж, но редко способствует увеличению производительности.
Что следует оптимизировать?
Общее правило гласит, что первая версия системы должна быть как можно проще. Оптимизировать следует только те части системы, которые, очевидно, будут предоставлять собой проблему, поэтому их оптимизация является неизбежной. Одним из таких примеров является наличие блочного кэша для файловой системы. Как только операционная система отлажена до работоспособного состояния, следует произвести тщательные измерения, чтобы понять, на что действительно тратится время. Опираясь на эти числа, следует заниматься оптимизацией в тех областях, в которых это будет наиболее полезно.
Вот правдивая история о том, как оптимизация принесла больше вреда, чем пользы. Один из студентов автора Э́ндрю Стюарта Таненба́ума написал программу mkfs для системы MINIX. Эта программа создает пустую файловую систему на только что отформатированном диске. На оптимизацию этой программы студент затратил около шести месяцев. Когда он попытался запустить эту программу, оказалось, что она не работает, после чего потребовалось еще шесть дополнительных месяцев на ее отладку. На жестком диске эту программу, как правило, запускают всего один раз, при установке системы. Она также только раз запускается для каждого гибкого диска — после его форматирования. Каждый запуск программы занимает около 2 секунд. Даже если бы работа неоптимизированной версии занимала минуту, все равно затраты времени на оптимизацию столь редко используемой программы являлись бы непроизводительным расходованием ресурсов.
Лозунг, применимый к оптимизации производительности, мог бы звучать так: «Лучшее — враг хорошего».
Под этим мы подразумеваем, что как только удается достичь приемлемого уровня производительности, то попытки выжать последние несколько процентов, видимо, уже не стоят затрачиваемых усилий и усложнения программы. Если алгоритм планирования достаточно хорош и обеспечивает 90 %-ную загрузку центрального процессора, возможно, этого достаточно. Разработка значительно более сложного алгоритма, на 5 % лучше имеющегося, не всегда представляет собой удачную идею. Аналогично если частота подкачки страниц довольно низка, то есть подкачка не является узким местом, то, как правило, нет смысла лезть из кожи вон, чтобы добиться оптимальной производительности. Недопущение сбоев в работе системы представляется намного более важной задачей, нежели достижение оптимальной производительности, особенно если алгоритм, оптимальный при одном уровне загруженности компьютера, может оказаться неоптимальным при другом уровне. Другим вопросом является такой: что оптимизировать и когда? Некоторые программисты, как только что-либо заработает, стремятся оптимизировать абсолютно все, что они разрабатывают. Проблема в том, что после оптимизации система может стать менее понятной и более сложной для обслуживания и отладки. Кроме того, ее будет труднее адаптировать, а позднее, возможно, оптимизировать удачнее. Эта проблема называется преждевременной оптимизацией. Дональд Кнут, которого иногда называют отцом анализа алгоритмов, однажды сказал:
«Преждевременная оптимизация является корнем всех зол».
Выбор между оптимизацией по скорости и по занимаемой памяти
При увеличении производительности программы приходится идти на компромисс между сокращением времени выполнения программы и увеличением занимаемой ею памяти. Программисты часто оказываются перед выбором между медленным, но компактным алгоритмом и более быстрым, но занимающим значительно больше памяти. Занимаясь важной оптимизацией, следует искать алгоритмы, дающие увеличение скорости за счет использования большего объема памяти или, наоборот, сберегающие драгоценную память за счет выполнения большего количества вычислений.
Иногда может быть полезен метод, заключающийся в замене небольших процедур макросами. Использование макроса устраняет накладные расходы, связанные с вызовом процедуры. Выигрыш оказывается особенно существенным, если процедура вызывается многократно в цикле. Например, предположим, что мы используем битовый массив для учета ресурсов и нам часто приходится узнавать, сколько единиц свободно в некоторой области битового массива. Для этой цели нужна процедура bit_count, считающая количество единичных битов в байте. Простая процедура показана в листинге 2, а. Эта процедура в цикле перебирает биты в байте, считая их по одному на каждом цикле. Все довольно просто и понятно.
Листинг 2. а — процедура для подсчета битов в байте; б — макрос для подсчета битов; в — макрос для поиска числа битов в таблице
#define BYTE_SIZE 8 /* Байт содержит 8 бит */ int bit_count(int byte)
{ /* Подсчет битов в байте */
int i, count = 0;
for (i = 0; i < BYTE_SIZE; i++) /* Цикл по битам байта */
if ((byte >> i) & 1) count++; /* если бит равен 1, увеличить на
единицу сумму */
return(count); /* вернуть сумму */
}
а
/* Макрос для подсчета суммы битов в байте */
#define bit_count(b) (b&1) + ((b>>1)&1) + ((b>>2)&1) + ((b>>3)&1) + \ ((b>>4)&1) + ((b>>5)&1) + ((b>>6)&1) + ((b>>7)&1)
б
/* Макрос для поиска числа битов в таблице */
char bits[256] = {0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4, 1, 2, 2, 3, 2,
3, 3, …};
#define bit_count(b) (int) bits[b]
в
У этой процедуры два источника неэффективности. Во-первых, ей нужно передавать управление, для чего требуется выделение стека, а после работы процедура должна вернуть результат и управление. Эти накладные расходы есть у каждого вызова процедуры. Во-вторых, процедура содержит цикл, а с циклом всегда связаны определенные накладные расходы.
Совершенно иной подход применен при использовании макроса в листинге 2 б. Это выражение вычисляет сумму битов, последовательно сдвигая аргумент и выделяя при помощи маски младший бит. Этот макрос трудно назвать произведением искусства, но он встречается в программе всего один раз. Вызов этого макроса выглядит идентично вызову процедуры:
sum = bit_count(table[i]);
Таким образом, если не считать несколько беспорядочного определения, макрос вы глядит не хуже процедуры, но является намного более эффективным, так как в случае макроса устраняются накладные расходы процедурного вызова и накладные расходы цикла.
Оптимизация данного алгоритма может быть продолжена. Зачем вообще считать сумму битов? Почему не посмотреть результат в таблице? В конце концов, байт может принимать всего 256 значений, а число битов в байте может быть от 0 до 8. Мы можем объявить массив bits из 256 значений, содержащий значения сумм битов, инициализируемые во время компиляции программы. При таком методе во время работы программы потребуется всего одна команда обращения к массиву по индексу. Соответствующий макрос показан в листинге 3, в.
Показанные ранее макросы представляют собой понятные примеры выигрыша в скорости за счет увеличения размеров программы. Однако в деле оптимизации мы могли бы пойти еще дальше. Если требуется количество битов в 32разрядном слове, то с помощью макроса bit_count нам потребовалось бы для каждого слова выполнить четыре обращения к массиву. Если мы увеличим размер таблицы до 65 536 элементов, то сможем обойтись всего двумя обращениями к таблице на слово за счет значительного увеличения таблицы.
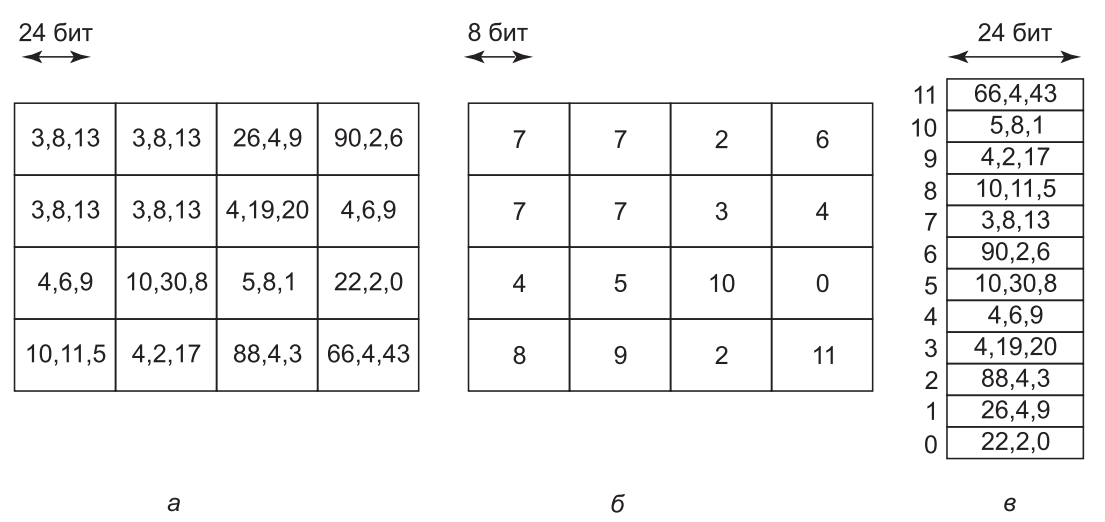 Поиск значений в таблице может использоваться и в других ситуациях. В общеизвестной технологии сжатия изображений GIF для кодирования 24-разрядных пикселов формата RGB применяется поиск в таблице. Но алгоритм GIF работает только с изображениями, содержащими не более 256 цветов. Для каждого сжимаемого изображения формируется палитра из 256 цветов, хранящихся в формате RGB. Сжатое изображение состоит из 8разрядных индексов таблицы вместо 24-разрядных значений цвета, благодаря чему достигается сжатие в три раза. Эта идея проиллюстрирована для фрагмента изображения 4 × 4 пиксела на рис. 12.4. Несжатое изображение показано на рис. 12.4, а. Каждый пиксел здесь представляет собой 24-разрядное число, в котором каждый из трех байтов содержит интенсивность красного, зеленого и синего цвета. Соответствующее этому фрагменту изображение в формате GIF показано на рис. 12.4, б. Палитра цветов, показанная на рис. 12.4, в, хранится прямо в файле GIF. В действительности формат GIF несколько сложнее, но основная идея заключается в применении таблицы цветов.
Поиск значений в таблице может использоваться и в других ситуациях. В общеизвестной технологии сжатия изображений GIF для кодирования 24-разрядных пикселов формата RGB применяется поиск в таблице. Но алгоритм GIF работает только с изображениями, содержащими не более 256 цветов. Для каждого сжимаемого изображения формируется палитра из 256 цветов, хранящихся в формате RGB. Сжатое изображение состоит из 8разрядных индексов таблицы вместо 24-разрядных значений цвета, благодаря чему достигается сжатие в три раза. Эта идея проиллюстрирована для фрагмента изображения 4 × 4 пиксела на рис. 12.4. Несжатое изображение показано на рис. 12.4, а. Каждый пиксел здесь представляет собой 24-разрядное число, в котором каждый из трех байтов содержит интенсивность красного, зеленого и синего цвета. Соответствующее этому фрагменту изображение в формате GIF показано на рис. 12.4, б. Палитра цветов, показанная на рис. 12.4, в, хранится прямо в файле GIF. В действительности формат GIF несколько сложнее, но основная идея заключается в применении таблицы цветов.
![]()
Рис. 1. Фрагмент изображения с 24 битами на пиксел:
а — несжатый;
б — сжатый при помощи алгоритма GIF с 8 битами на пиксел;
в — палитра цветов
Существует и другой способ уменьшить размер изображения, служащий иллюстрацией еще одного компромисса. Для описания изображений может использоваться язык программирования PostScript. (В действительности для этой цели может применяться любой язык, но PostScript предназначен именно для этого.) Многие принтеры имеют встроенный интерпретатор языка PostScript.
Например, если на изображении имеется прямоугольный блок пикселов одного цвета, программа на языке PostScript для этого изображения будет содержать команды для помещения прямоугольника в определенное место изображения и заполнения его определенным цветом. Для хранения этих команд потребуется всего несколько битов. Когда принтер получает изображение, интерпретатор запускает программу и создает изображение. Таким образом, язык PostScript позволяет добиться сжатия данных за счет большего объема вычислений. Этот подход диаметрально противоположен рассматривавшемуся ранее примеру оптимизации по скорости с поиском значения в таблице, но он также очень полезен, когда не хватает памяти или пропускной способности.
Кэширование
Хорошо известным методом повышения производительности является кэширование. Оно может применяться каждый раз, когда с большой вероятностью можно предсказать, что много раз потребуется один и тот же результат. Общий метод заключается в том, чтобы выполнить всю работу в первый раз, а затем сохранить результат в кэше. При последующих попытках в первую очередь будет проверяться кэш. Если результат находится в кэше, то нужно всего лишь достать его оттуда. В противном случае необходимо проделать всю работу сначала.
Мы уже наблюдали использование кэша в файловой системе, где он хранит некоторое количество недавно использовавшихся блоков диска, что позволяет избежать об ращения к диску при чтении блока. Однако кэширование может применяться и для других целей. Например, обработка путей к файлам отнимает удивительно много процессорного времени. Рассмотрим снова пример из системы UNIX, показанный на рис. 6.35. Чтобы найти файл /usr/ast/mbox, потребуется выполнить следующие обращения к диску:
-
-
-
- Прочитать i-узел корневого каталога (i-узел 1).
- Прочитать корневой каталог (блок 1).
- Прочитать i-узел каталога /usr (i-узел 6).
- Прочитать каталог /usr (блок 132).
- Прочитать i-узел каталога /usr/ast (i-узел 26).
- Прочитать каталог /usr/ast (блок 406).
-
-
Чтобы просто определить номер i-узла искомого файла, нужно как минимум шесть раз обратиться к диску. Если размер файла меньше размера блока (например, 1024 байт), то чтобы прочитать содержимое файла, нужны восемь обращений к диску.
В некоторых операционных системах обработка путей файлов оптимизируется при помощи кэширования пар (путь, i-узел). Например, на рис. 6.35 кэш будет содержать первые три записи табл. 12.1 после обработки пути /usr/ast/mbox. Последние три записи попадают в таблицу после обработки других путей.
Таблица 1. Часть кэша i-узлов
| Путь | Номер i-узла |
| /usr | 6 |
| /usr/ast | 26 |
| /usr/ast/mbox | 60 |
| /usr/ast/books | 92 |
| /usr/bal | 45 |
| /usr/bal/papers.ps | 85 |
Когда файловая система должна найти файл по пути, обработчик путей сначала обращается к кэшу и ищет в нем самую длинную подстроку, соответствующую обрабатываемому пути. Если обрабатывается путь /usr/ast/grants/stw, кэш отвечает, что номер i-узла каталога /usr/ast равен 26, так что поиск может быть начат с этого места и количество обращений к диску уменьшено на четыре.
Недостаток кэширования путей состоит в том, что соответствие имени файла номеру его i-узла не является постоянным. Представьте, что файл /usr/ast/mbox удаляется и его i-узел используется для другого файла, владельцем которого может быть другой поль зователь. Затем файл /usr/ast/mbox создается снова, но на этот раз он получает i-узел с номером 106. Если не предпринять специальных мер, запись кэша будет указывать на неверный номер i-узла. Поэтому при удалении файла или каталога следует удалять из кэша запись, соответствующую этому файлу, а если удаляется каталог, то следует удалить также все записи для содержавшихся в этом каталоге файлов и подкаталогов.
Кэшироваться могут не только блоки дисков и пути к файлам. Можно кэшировать также i-узлы. Если для обработки прерываний используются временные потоки, для каждого из них требуется стек и некоторый дополнительный механизм. Эти использовавшиеся ранее потоки также можно кэшировать, так как обновить уже использовавшийся поток легче, чем создать новый (применение кэша позволяет избежать необходимости в выделении памяти новому процессу). Кэширование может применяться почти для всего, что трудновоспроизводимо.
Подсказки
Элементы кэша всегда должны быть корректными. Поиск в кэше может завершиться неудачей, но если элемент найден, то его корректность гарантируется, поэтому найденный элемент может использоваться без дополнительных хлопот. В некоторых системах бывает удобно содержать таблицу подсказок. Подсказки представляют собой предложения решений, но их корректность не гарантируется. Обращающийся к этой таблице процесс должен сам проверять корректность результата.
Хорошо известным примером подсказок являются указатели URL, содержащиеся в веб-страницах. Когда пользователь щелкает мышью на ссылке, он не получает гарантии, что соответствующая веб-страница находится там, куда указывает URL. В действительности может оказаться, что требующаяся страница удалена несколько лет назад. Таким образом, информация, содержащаяся на веб-странице, представляет собой всего лишь подсказку.
Подсказки используются также при работе с удаленными файлами. Информация, содержащаяся в подсказке, сообщает нечто об удаленном файле, например его место нахождение. Однако, возможно, этот файл уже удален или перемещен в другое место, поэтому всегда требуется проверка корректности подсказки.
Использование локальности
Процессы и программы действуют не случайным образом. Они оказываются в значительной степени локальными как во времени, так и в пространстве, и эта информация может быть использована различными способами для улучшения производительности. Один хорошо известный пример пространственной локальности заключается в том факте, что процессы не прыгают произвольным образом в пределах своего адресного пространства. Как правило, за фиксированный интервал времени они используют относительно небольшое количество страниц. Страницы, активно используемые процессом, могут рассматриваться как рабочий набор процесса. А операционная система может гарантировать, что этот рабочий набор находится в памяти, когда процесс получает управление, тем самым снижается количество страничных прерываний.
Принцип локальности применим и для файлов. Когда процесс выбирает конкретный рабочий каталог, многие из его последующих файловых обращений, скорее всего, будут относиться к файлам, расположенным в этом каталоге. Производительность можно повысить, если поместить все файлы каталога и их i-узлы близко друг к другу на диске. Именно этот принцип лежит в основе файловой системы Berkeley Fast File System (McKusick et al., 1984).
Другой областью, в которой локальность играет важную роль, является планирование потоков в мультипроцессорах. Как было показано в главе 8, один из методов планирования потоков заключается в том, чтобы попытаться запустить каждый поток на том центральном процессоре, на котором он работал в прошлый раз, в надежде, что какие-нибудь из его блоков все еще находятся в кэше.
Оптимизируйте общий случай
Часто бывает полезно различать наиболее частый случай и наименее вероятный случай и обращаться с ними по-разному. Обычно различные случаи обрабатываются разными программами. Важно, чтобы частый случай работал быстро. От алгоритма для редко встречающегося случая достаточно добиться корректной работы.
В качестве первого примера рассмотрим вхождение в критическую область. В большинстве случаев процессу будет удаваться вход в критическую область, особенно если внутри этой области процессы проводят не много времени. Операционная система Windows 10 использует это преимущество, предоставляя вызов WinAPI EnterCriticalSection, который является атомарной функцией, проверяющей флаг в режи ме пользователя (с помощью команды процессора TSL или ее эквивалента). Если тест проходит успешно, процесс просто входит в критическую область, для чего не требуется обращения к ядру. Если же результат проверки отрицательный, библиотечная про цедура выполняет на семафоре операцию down, чтобы заблокировать процесс. Таким образом, если все нормально, обращения к ядру не требуется. В главе 2 мы видели, что фьютексы в Linux также оптимизированы для общего случая отсутствия конкуренции.
В качестве второго примера рассмотрим установку будильника, использующего сигналы UNIX. Если в текущий момент ни один будильник не заведен, то просто создается запись и помещается в очередь таймеров. Однако если будильник уже заведен, его следует найти и удалить из очереди таймера. Так как системный вызов alarm не указывает, установлен ли уже будильник, система должна предполагать худшее, то есть что он уже заведен. Однако в большинстве случаев будильник не будет заведен, и поскольку удаление существующего будильника представляет собой дорогое удовольствие, то следует различать эти два случая.
Один из способов достижения этой цели заключается в том, чтобы хранить в таблице процессов бит, указывающий, заведен ли будильник. Если бит сброшен, то программа следует по простому пути (просто добавляется новая очередь таймера без какой-либо проверки). Если бит установлен, то очередь таймера требует проверки.
Вопрос 4. Управление проектом.
Многие программисты являются вечными оптимистами. Они полагают, что для того, чтобы написать программу, нужно всего лишь поскорее сесть за клавиатуру и начать набивать символы. Вскоре после этого появится полностью законченная отлаженная программа. Очень большие программы таким способом написать невозможно. В следующих разделах мы кратко обсудим вопросы управления большими программными проектами, особенно управления большими системными проектами.
4.1. Мифический человеко-месяц.
В своей классической книге «The Mythical Man Month» Фред Брукс, один из разработчиков системы OS/360, занявшийся впоследствии научной деятельностью, рассматривает вопрос, почему так трудно построить большую операционную систему (Brooks, 1975, 1995). Когда большинство программистов встречают с его утверждение, что специалисты, работающие над большими проектами, могут за год произвести всего лишь 1000 строк отлаженного кода, они удивляются, не прилетел ли профессор Брукс из космоса, с планеты Баг. Ведь большинство из них помнят, как они создавали программу из 1000 строк всего за одну ночь. Как же этот объем исходного текста может составлять годовую норму для любого программиста, чей IQ превышает 50?
Брукс отмечает, что большие проекты, в которых задействованы сотни программистов, принципиально отличаются от небольших проектов и что результаты, достигнутые при работе над небольшим проектом, нельзя переносить на большой проект. В большом проекте огромное количество времени тратится на планирование того, как разделить работу на отдельные модули. При этом нужно детально расписать работу модулей и интерфейсы к ним, а также попытаться представить себе, как эти модули взаимодействуют, причем до того, как начнется само программирование. Затем модули по отдельности создаются и отлаживаются. Наконец, модули собираются вместе и вся система в целом тестируется. Как правило, при этом собранная из работающих по от дельности модулей система работать не хочет и после сборки и запуска немедленно рушится. Брукс оценивает количество работ следующим образом:
- 1/3 — планирование;
- 1/6 — кодирование;
- 1/4 — тестирование модулей;
- 1/4 — тестирование системы.
Другими словами, собственно написание программы представляет собой самую простую часть проекта. Самым сложным оказывается решить, какими должны быть модули, а также заставить эти модули корректно общаться друг с другом. В небольшой программе, создаваемой одним программистом, планирование составляет как раз наиболее легкую часть.
Заголовком книги Брукс обращает внимание читателя на собственное утверждение о том, что люди и время не взаимозаменяемы. Такой единицы, как человеко-месяц, в программировании не существует. Если в проекте участвуют 15 человек и на всю работу у них уходит 2 года, отсюда не следует, что 360 человек справятся с этой работой за один месяц и вряд ли 60 человек выполнят ее за 6 месяцев.
У этого явления есть три причины. Во-первых, работа не может быть полностью разделена. До тех пор, пока не будет закончено планирование и не будет определено, какие модули нужны, а также какими будут интерфейсы, никакое программирование не может даже начаться. При двухлетнем проекте одно лишь планирование может занять 8 месяцев.
Во-вторых, чтобы полностью использовать большое число программистов, работу следует разделить на большое количество модулей, чтобы всех обеспечить работой. Поскольку потенциально каждый модуль взаимодействует с каждым модулем, число рассматриваемых пар «модуль — модуль» растет пропорционально квадрату от числа модулей, то есть квадрату числа программистов. Поэтому большие проекты с увеличением числа программистов очень быстро выходят из под контроля. Тщательные измерения 63 программных проектов подтвердили, что зависимость времени выполнения проекта от количества программистов далеко не так проста, как можно предположить, исходя из концепции человеко-месяцев (Boehm, 1981).
В-третьих, процесс отладки в большой степени является последовательным. Если усадить за решение проблемы вместо одного отладчика десятерых, это не поможет обнаружить ошибку в программе в десять раз быстрее. На самом деле десять отладчиков, вероятно, будут работать даже медленнее одного, так как они станут тратить очень много времени на разговоры друг с другом.
Брукс подводит итоги своего опыта знакомства с большими проектами, формулируя следующий закон (закон Брукса): «Добавление к программному проекту на поздней стадии дополнительных людских сил приводит к увеличению сроков выполнения проекта».
Недостаток введения в проект новых людей состоит в том, что их необходимо обучать, модули нужно делить заново, чтобы их число соответствовало числу программистов, требуется провести множество собраний, чтобы скоординировать работу отдельных групп и программистов, и т. д. Абдель Хамид и Медник (Abdel Hamid and Madnick, 1991) получили экспериментальное подтверждение этого закона. Слегка фривольный вариант закона Брукса звучит так: «Если собрать девять беременных женщин в одной комнате, то они не родят через один месяц».
Структура команды
Коммерческие операционные системы представляют собой большие программные проекты, которые требуют участия в работе больших команд разработчиков. Уровень программистов имеет чрезвычайно большое значение. Уже десятки лет известно, что сильнейшие программисты в десять раз продуктивнее плохих программистов (Sackman et al., 1968). Неприятность заключается в том, что когда вам нужны 200 программистов, сложно найти 200 программистов высочайшей квалификации. Вам придется согласиться на команду, состоящую из программистов самого разного уровня.
Что также важно в крупном проекте, программном или любом другом, — это необходимость архитектурного соответствия. Нужно, чтобы один человек контролировал всю конструкцию. В качестве примера Брукс приводит кафедральный собор в Реймсе, постройка которого заняла десятки лет, но архитекторы, сменявшие друг друга, не под дались искушению внести в проект собственные идеи и сумели сохранить изначальный архитектурный план. В результате было получено архитектурное соответствие, которого не удалось достичь в других соборах Европы.
В 1970е годы Харлан Миллс попытался объединить наблюдения о различиях в уровнях квалификации программистов с необходимостью архитектурного соответствия и ввел понятие команды главного программиста (Baker, 1972). Его идея заключалась в том, чтобы организовать программистов в нечто подобное хирургической группе в противоположность бригаде забойщиков свиней. В отличие от последней команды, в которой у каждого работника по ножу и он рубит им направо и налево как сумасшедший, в хирургической группе только один хирург держит в руке скальпель. Остальные члены группы лишь ассистируют ему. Предложенная Миллсом структура команды из 10 разработчиков показана в табл. 12.2.
Таблица 1. Предложенная Миллсом структура команды из 10 разработчиков
| Должность | Обязанности |
| Главный программист | Занимается архитектурным дизайном и пишет программу |
| Второй пилот | Помогает главному программисту и служит резонатором |
| Администратор | Управляет людьми, бюджетом, пространством, оборудованием, отчетами и т. Д. |
| Редактор | Редактирует документацию, которую должен писать главный программист |
| Секретари | Администратору и редактору нужны секретари |
| Архивариус | Следит за состоянием архивов программ и документации |
| Инструментальщик | Снабжает главного программиста необходимыми инструментами |
| Тестер | Тестирует программы главного программиста |
| Эксперт по языкам | (Работает неполный рабочий день.) Может дать главному программисту совет по языкам программирования |
Такая структура команды была предложена 30 лет назад. С тех пор кое-что изменилось (так, например, исчезла надобность в консультанте по языкам — язык C проще, чем PL/1). Но необходимость в централизованном управлении осталась. По-прежнему управлять всей схемой должен всего один человек. Хотя использование компьютеров позволяет уменьшить штат помощников, но сама идея все еще остается в силе.
Любой большой проект должен быть организован иерархически. На нижнем уровне располагается множество маленьких групп, каждую из которых возглавляет главный программист. На следующем уровне группы команд должны координироваться менеджером. Как показывает опыт, каждый управляемый менеджером человек обходится ему в 10 % рабочего времени, поэтому для каждой группы из 10 команд требуется отдельный менеджер. Этими менеджерами также нужно управлять, и так далее до вершины дерева.
Брукс отмечает, что плохие новости плохо распространяются вверх по дереву. Джерри Зальтцер из Массачусетского технологического института назвал этот эффект диодом плохих новостей. Ни один программист или менеджер не хочет сообщать своему боссу, что проект на 4 месяца отстает от графика и не имеет шансов быть выполненным в срок, из-за тысячелетней традиции отрубания головы посланнику, принесшему дурную новость. В результате старший менеджер, как правило, не имеет никакого представления о состоянии проекта. Когда становится совершенно очевидно, что в срок проект выполнен быть не может ни при каких условиях, старший менеджер нанимает дополнительных людей, после чего в действие вступает закон Брукса.
На практике большие компании, у которых накоплен значительный опыт в области производства программного обеспечения и которые знают, что произойдет, если оно создается бессистемно, по крайней мере пытаются действовать правильно. Небольшие новые компании, изо всех сил спешащие прорваться на рынок, напротив, не всегда заботятся о том, чтобы аккуратно производить свое программное обеспечение. Эта спешка часто приводит к далеко не оптимальным результатам.
Ни Брукс, ни Миллс не могли предвидеть такого роста производства открытых программных средств. Хотя многие сомневаются (особенно те, кто возглавляет крупные компании по разработке программного обеспечения), программы с открытым кодом пользуются огромным успехом. Они применяются повсюду, от больших серверов до встроенных устройств и от промышленных систем управления до смартфонов. Такие крупные компании, как Google и IBM, теперь прикладывают значительные силы к совершенствованию операционной системы Linux и вносят немалый вклад в ее код. Следует заметить, что наиболее удачные проекты открытых программных средств, несомненно, использовали модель главного программиста, то есть всем проектом управлял один человек (например, Линус Торвальдс, руководивший разработкой ядра операционной системы Linux, и Ричард Столман, направлявший процесс создания компилятора GNU C).
Роль опыта
Наличие опытных разработчиков играет важнейшую роль для любого проекта по разработке программного обеспечения. Брукс указывает, что большинство ошибок допускают не при программировании, а на стадии проекта. Программисты правильно делают то, что им велят делать. Но если то, что им велели, было неверно, то никакое тестовое программное обеспечение не сможет поймать ошибку неверно составленной спецификации.
Решение, предложенное Бруксом, заключается в отказе от классической модели раз работки (рис. 12.5, а) и использовании модели, показанной на рис. 12.5, б. Принцип состоит в том, чтобы сначала написать главный модуль программы, который просто вызывает процедуры верхнего уровня. Вначале эти процедуры представляют собой заглушки. Начиная уже с первого дня система будет транслироваться и запускаться, хотя делать она ничего не будет. Постепенно заглушки заменяются модулями. Результат применения такого метода заключается в том, что сборка системы проверяется постоянно, поэтому ошибки в проекте обнаруживаются значительно раньше. Таким образом, процесс обучения на собственных ошибках также начинается значительно раньше.
Неполные знания опасны. В своей книге Брукс описывает явление, названное им эффектом второй системы. Часто первый продукт, созданный группой разработчиков, является минимальным, так как они опасаются, что он не будет работать вообще. Поэтому они не помещают в первый выпуск программного обеспечения много функций. Если проект оказывается удачным, они создают следующую версию программного обеспечения. Воодушевленные собственным успехом, во второй раз разработчики включают в систему все погремушки и побрякушки, намеренно не включенные в первый выпуск. В результате система раздувается и ее производительность снижается. От этой неудачи команда разработчиков 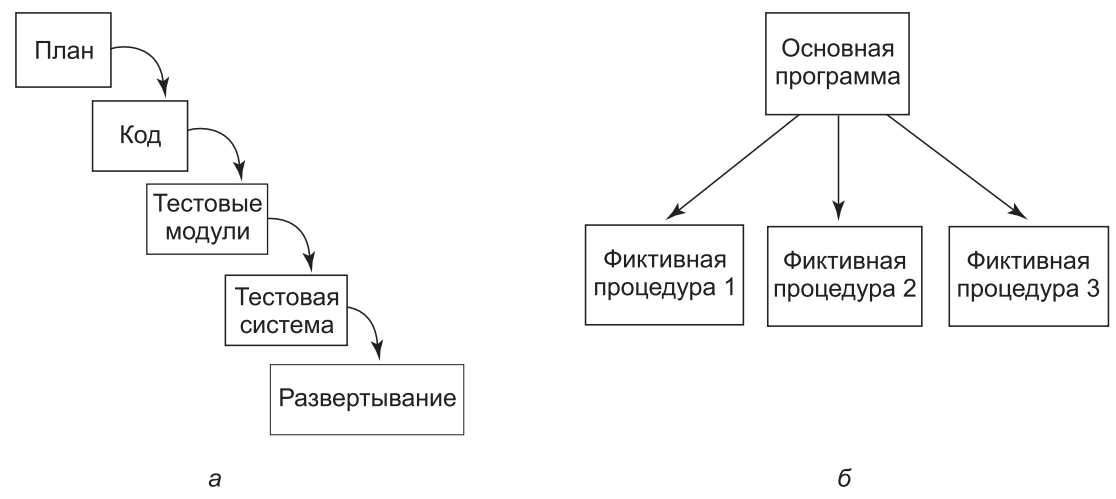 трезвеет и при выпуске третьей версии снова соблюдает осторожность.
трезвеет и при выпуске третьей версии снова соблюдает осторожность.
Рис. Проектирование программного обеспечения: а — традиционное поэтапное; б — альтернативный метод создания работающей уже с первого дня системы
Это наблюдение отчетливо видно на примере пары систем CTSS — MULTICS. Операционная система CTSS была первой универсальной системой разделения времени, и ее успех был огромен, несмотря на минимальную функциональность системы. Создатели операционной системы MULTICS, преемницы CTSS, были слишком амбициозны, за что и поплатились. Сами идеи были неплохи, но новых функций добавилось слишком много, что привело к низкой производительности системы, страдавшей этим недугом в течение долгих лет и так и не получившей коммерческого успеха. Третьей в этой линейке была операционная система UNIX, разработчики которой проявили значительно большую осторожность и в результате добились существенно больших успехов.
Панацеи нет
Помимо книги «Мифический человекомесяц», Брукс написал также статью «No Silver Bullet» (Панацеи нет) (Brooks, 1987), получившую широкий резонанс. В ней он доказывал, что в ближайшие 10 лет ни одно средство, поисками которого в те времена занималось множество людей, не приведет к существенному (на порядок) увеличению производительности при создании программного обеспечения. Как показывает опыт последних лет, он был прав.
Среди предлагавшихся в то время чудодейственных средств были улучшенные языки высокого уровня, объектно-ориентированное программирование, искусственный интеллект, экспертные системы, автоматическое программирование, графическое программирование, верификация программ и программное окружение. Возможно, в следующие 10 лет мы увидим нечто радикальное, но не исключено, что нам придется довольствоваться постепенными последовательными улучшениями.
Вопрос 5. Тенденции в проектировании операционных систем
В 1899 году Чарльз Дьюэл, возглавлявший тогда бюро патентов США, предложил тогдашнему президенту США МакКинли ликвидировать патентное бюро (а также рабочее место Чарльза Дьюэла!), поскольку, как он писал, «все, что можно было изобрести, уже изобретено» (Cerf and Navasky, 1984). Тем не менее прошло всего несколько лет, и на пороге патентного бюро показался Томас Эдисон с заявками на электрические лампы, фонограф и кинопроектор. Дело в том, что мир все время меняется, и операционные системы должны постоянно адаптироваться под новые реалии. В этой главе упоминался ряд тенденций, которые сегодня должны учитывать разработчики операционных систем.
Чтобы избежать путаницы: разработки в области оборудования, упоминаемые далее, уже существуют. Нет только программного обеспечения операционных систем для их эффективного использования. Обычно когда появляется новое оборудование, все просто накидывают на него старое программное обеспечение (Linux, Windows, и т. д.) и считают, что все в порядке. В конечном счете ничего хорошего в этом нет. Для работы с передовым оборудованием требуется передовое программное обеспечение. Придумать его — задача для ученых, занимающихся компьютерными технологиями, студентов соответствующего профиля или профессионалов в области информационных технологий.
Виртуализация и облако
Виртуализация относится к тем идеям, которые постоянно витают в воздухе. Впервые она была реализована в 1967 году на базе IBM CP/CMS, а теперь вернулась уже на платформе x86. Гипервизоры, взаимодействующие непосредственно с оборудованием (рис. 12.6), работают уже на многих компьютерах. Гипервизор создает множество виртуальных машин, обладающих собственными операционными системами. В наши дни многие компании подхватывают эту идею, виртуализируя и другие ресурсы. Например, повышенный интерес проявляют к виртуализации управления сетевым оборудованием. Этот интерес идет еще дальше — к вопросам запуска управления сетями в облаке. Кроме того, поставщики и исследователи ведут постоянную работу по совершенствованию гипервизоров по ряду показателей, делая их меньше и быстрее, а также повышая их гарантируемые изоляционные свойства.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Рис. 12.6. Гипервизор, работающий с четырьмя виртуальными машинами
Многоядерные микропроцессоры
Возникает вполне очевидный вопрос: что со всеми этими ядрами делать? Если запущен популярный сервер, обрабатывающий тысячи клиентских запросов в секунду, ответ может быть относительно простым. Например, можно решить выделить по ядру на каждый запрос. Если предположить, что ситуации с блокировками будут возникать не слишком часто, это может сработать. Ну а что делать со всеми этими ядрами на планшетных компьютерах?
Есть и еще один вопрос: какого типа ядра нам нужны? Суперскалярные ядра с глубокой конвейеризацией с предполагаемой выдающейся производительностью спекулятивных вычислений на высоких тактовых частотах могут великолепно себя проявить при выполнении последовательного кода. Но не слишком подойдут, если в работе прослеживается большой объем параллельных вычислений. Многие приложения лучше себя чувствуют с небольшими и простыми ядрами, если получают их в большом количестве. Некоторые специалисты ратуют за гетерогенные мультиядра, но возникает тот же самый вопрос: какие именно ядра, в каком количестве и с какими скоростями работы? И это мы даже не упомянули о вопросах работы операционной системы и всех ее приложений. Будет ли операционная система работать на всех ядрах или только на некоторых из них? Будет ли один или несколько сетевых комплектов? Какой объем совместно используемых ресурсов понадобится? Будут ли конкретные ядра выделяться конкретным функциям операционной системы (например, сетевому комплекту или комплекту хранения данных)? Если будут, то станут ли эти функции тиражироваться для лучшей масштабируемости?
Исследуя множество различных направлений, мир разработчиков операционных систем сейчас стремится сформулировать ответы на эти вопросы. Хотя у исследователей могут быть расхождения по тем или иным вопросам, большинство из них сходятся в одном: для системных исследований настали замечательные времена!
Операционные системы с большим адресным пространством
По мере того как на смену 32-разрядным машинам приходят 64-разрядные, становится возможным главное изменение в строении операционных систем. 32-разрядное адресное пространство на самом деле не так уж велико. Если попытаться разделить 232 байт на всех жителей Земли, то каждому достанется менее одного байта. В то же время 264 примерно равно 2 1019. При этом в 64-разрядном адресном пространстве каждому жителю планеты можно выделить фрагмент размером 3 Гбайт.
Что можно сделать с адресным пространством в 2 · 1019 байт? Для начала мы можем отказаться от концепции файловой системы. Вместо этого все файлы можно постоянно хранить в памяти (виртуальной). В конце концов, в ней достаточно места для более чем миллиарда полнометражных фильмов, сжатых до 4 Гбайт.
Другая возможность заключается в использовании перманентных объектов. Объекты могут создаваться в адресном пространстве и храниться в нем до тех пор, пока не будут удалены все ссылки на объект, после чего сам объект автоматически удаляется. Такие объекты будут сохраняться в адресном пространстве даже после выключения и перезагрузки компьютера. Чтобы заполнить все 64разрядное адресное пространство, нужно создавать объекты со скоростью 100 Мбайт/с в течение 5000 лет. Разумеется, для хранения такого количества данных потребуется очень много дисков, но впервые в истории ограничивающим фактором стали физические возможности дисков, а не адресное пространство.
При большом количестве объектов в адресном пространстве становится интересно позволить нескольким процессам работать одновременно в одном адресном пространстве, чтобы упростить совместное использование объектов. Применение такой схемы, разумеется, приведет к появлению операционных систем, сильно отличающихся от существующих в настоящий момент. Еще один системный аспект, который придется пересмотреть при введении 64разрядных адресов, — это виртуальная память. При 264 байт виртуального адресного пространства и восьмикилобайтных страницах у нас будет 251 страниц. Работать с обычными таблицами страниц такого размера будет не просто, поэтому потребуется другое решение. Возможно использование инвертированных таблиц страниц, однако предлагались и другие идеи (Talluri et al., 1995). В любом случае, появление 64разрядных операционных систем создает новую большую область исследований.
Беспрепятственный доступ к данным
На заре развития вычислительной техники существовала значительная разница между той и этой машинами. Если данные были на этой машине, получить к ним доступ с той машины было невозможно, если только они не были на нее предварительно перенесены. Кроме того, если у вас имелись данные, вы не могли ими воспользоваться, пока не было установлено соответствующее программное обеспечение. Но эта модель изменилась.
В наши дни пользователи ожидают, что можно получить доступ к большинству данных из любых мест и в любое время. Как правило, это достигается хранением данных в облачных структурах с использованием таких служб хранения данных, как Dropbox, GoogleDrive, iCloud и SkyDrive. Все хранящиеся там файлы могут быть доступны с любого устройства, имеющего сетевое подключение. Более того, программы для до ступа к данным зачастую также находятся в облачном хранилище, поэтому вам даже не нужно иметь их где-либо установленными. Это позволяет людям читать и изменять файлы текстового процессора, электронных таблиц и презентаций, используя смартфон в любом, даже самом необычном месте. Все это обычно выдается за прогресс.
Чтобы добиться абсолютной беспрепятственности, требуется немало скрытых от глаз хитроумных системных решений. Например, что делать, если нет сетевого подключения? Разумеется, не хотелось бы, чтобы работа людей прерывалась. Также понятно, что можно поместить изменения в локальный буфер и обновить основной документ при восстановлении подключения, но как быть, если на многих устройствах были про изведены конфликтующие друг с другом изменения? При совместном использовании данных эта проблема возникает довольно часто, но она может проявляться даже при единственном пользователе. Более того, если файл имеет большой размер, не хотелось бы долго ждать, пока к нему будет открыт доступ. Ключевыми вопросами здесь вы ступают кэширование, предварительная загрузка и синхронизация. У существующих сегодня операционных систем работа по объединению нескольких машин все еще имеет ряд существенных препятствий. И мы, конечно же, можем исправить ситуацию в этой области.
Компьютеры с автономным питанием
Мощные персональные компьютеры с 64разрядным адресным пространством, подключением к высокоскоростной сети, несколькими процессорами и высококачественными изображением и звуком теперь стали стандартом для настольных систем и быстро занимают область ноутбуков, планшетных компьютеров и смартфонов. Если эта тенденция сохранится, то чтобы обеспечить все эти запросы, их операционные системы должны будут существенно отличаться от сегодняшних систем. Кроме того, они должны будут выдерживать баланс энергопотребления и поддержания приемлемого температурного режима устройства. Тепловыделение и энергопотребление являются одними из наиболее важных проблем даже в компьютерах высокого класса. Но еще более быстро развивающийся сегмент рынка составляют компьютеры с автономным питанием, к которым относятся ноутбуки, планшеты, дешевые нетбуки и смартфоны. Большинство из них поддерживают беспроводное соединение с внешним миром. Для них нужны операционные системы, отличающиеся от операционных систем, разра ботанных для устройств высокого класса, меньшими размерами, большей скоростью, гибкостью и большей надежностью. Многие из этих устройств сейчас основаны на традиционных операционных системах, таких как Linux, Windows и OS X, но с суще ственными изменениями. Кроме того, для управления набором радиосредств в них часто используются решения на основе микроядер и гипервизоров.
Эти операционные системы должны лучше нынешних систем справляться с операциями полного подключения (по проводам), слабого подключения (по беспроводной связи) и автономной работой, включая накопление данных перед отключением от сети и проверку непротиворечивости данных перед новым подключением. В будущем им также придется лучше нынешних систем справляться с проблемами мобильности (например, находить лазерный принтер, регистрироваться на нем и посылать ему файл по радио). Особое значение для этих систем имеет управление энергопотреблением, включая продолжительные диалоги между операционной системой и приложениями о том, сколько осталось энергии в батареях и как ее лучше всего использовать. Также может стать важной динамическая адаптация приложений к крошечным экранам. Наконец, для новых режимов ввода и вывода, включая ввод рукописного текста и речевой ввод, в операционной системе могут потребоваться новые методы, позволяющие повысить качество. Скорее всего, операционная система портативного беспроводного управляемого голосом компьютера с автономным питанием будет существенно отличаться от системы, работающей на 64разрядном настольном компьютере с 16-ядерным центральным процессором с гигабитным оптоволоконным сетевым подключением. И разумеется, будет бесчисленное множество гибридных машин, имеющих собственные требования.
Встроенные системы
Последняя область, в которой будут плодиться и размножаться новые операционные системы, — это встроенные системы. Операционные системы в стиральных машинах, микроволновых печах, куклах, радиоприемниках, MP3проигрывателях, видеокамерах, лифтах и кардиостимуляторах будут отличаться от всех перечисленных ранее и, скорее всего, друг от друга. Каждая из них должна быть тщательно «скроена» под конкретное приложение, так как маловероятно, что кому-либо придет в голову засунуть карту PCIe в кардиостимулятор, чтобы превратить его в контроллер лифта. Поскольку во всех встроенных системах работает только ограниченный набор программ, известных заранее, можно запретить оптимизацию в универсальных системах.
Поскольку встроенные системы будут производиться сотнями миллионов, это станет главным рынком для операционных систем.
Заключение
Проектирование операционных систем начинается с определения их задач. Интерфейс должен быть простым, полным и эффективным. Он должен обладать ясной парадигмой пользовательского интерфейса, парадигмой исполнения и парадигмой данных.
Система должна быть хорошо структурированной, для чего может быть использована одна из нескольких известных технологий, таких как многоуровневые системы или архитектуры «клиент–сервер». Внутренние компоненты должны быть ортогональными друг к другу. Кроме того, следует четко отделить политику от механизма. Следует также уделить существенное внимание таким вопросам, как выбор между статическими или динамическими структурами данных, именование, время связывания, а также порядок реализации модулей.
Производительность является важным вопросом, но следует тщательно выбирать способ оптимизации, чтобы не нарушить структуру операционной системы. Часто имеет смысл заниматься оптимизацией по скорости или по занимаемой памяти, кэшированием, подсказками, использовать локальность, а также оптимизировать общий случай.
Создание системы группой из двух-трех человек отличается от разработки большой системы командой из 300 сотрудников. В последнем случае в успехе или неуспехе проекта главную роль играют такие вопросы, как структура команды и управление проектом.
Наконец, операционные системы претерпевают изменения, чтобы подстраиваться под новые веяния и отвечать новым вызовам. К ним могут относиться системы на основе гипервизоров, многоядерные системы, системы с 64-разрядным адресным пространством, мобильные компьютеры с беспроводной связью и встроенные системы.